一、遗忘算法诠释
这里“遗忘”不是笔误,这个系列要讲的“遗忘算法”,是以牛顿冷却公式模拟遗忘为基础、用于自然语言处理(NLP)的一类方法的统称,而不是大名鼎鼎的“遗传算法”!“遗忘算法”已经摸索研究了三年有余,现也算略成体系。

二、遗忘算法原理
能够从未知的事物中发现关联、提炼规律才是真正智能的标志,而遗忘正是使智能生物具备这一能力的工具,也是适应变化的利器,“遗忘”这一颇具负能量特征的家伙是如何实现发现规律这么个神奇魔法的呢?
我们还可以想像,狗在进食的时候听到的声音可能还有鸟叫声、风吹树叶的沙沙声,为什么这些同样具备重复特征声音却没有和开饭建立关系呢?
细分辨我们不难想到:铃声和开饭之间不仅重复共现,而且这种重复共现还具备一个相对稳定的周期,而其他的那些声音和开饭的共现则是随机的。
那么遗忘又在其中如何起作用的呢?
1、所有事物一视同仁的按相同的规律进行遗忘;
2、偶尔或随机出现的事物因此会随时间而逐渐淡忘;
3、而具有相对稳定周期重复再现的事物,虽然也按同样的规律遗忘,但由于周期性的得到补充,从而可以动态的保留在记忆中。
在自然语言处理中,很多对象比如:词、词与词的关联、模板等,都具备按相对稳定重现的特征,因此非常适用遗忘来处理。
三、牛顿冷却公式
那么,我们用什么来模拟遗忘呢?
提到遗忘,很自然的会想到艾宾浩斯遗忘曲线,如果这条曲线有个函数形式,那么无疑是模拟遗忘的最佳建模选择。遗憾的是它只是一组离散的实验数据,但至少让我们知道,遗忘是呈指数衰减的。另外有一个事实,有的人记性好些,有的人记性则差些,不同人之间的遗忘曲线是不同的,但这并不会从本质上影响不同人对事物的认知,也就是说,如果存在一个遗忘函数,它首先是指数形式的,其次在实用过程中,该函数的系数并不那么重要。
这提醒我们,可以尝试用一些指数形式的函数来代替遗忘曲线,然后用实践去检验,如果能满足工程实用就很好,这样的函数公式并不难找,比如:退火算法、半衰期公式等。
有次在阮一峰老师的博客上看关于帖子热度排行的算法时,其中一种方法使用的是牛顿冷却定律,遗忘与冷却有着相似的过程、简洁优美的函数形式、而且参数只与时间相关,这些都让我本能想到,它就是我想要的“遗忘公式”。
在实践检验中,牛顿冷却公式,确实有效好用,当然,不排除有其他更佳公式。

四、已经实现的功能
如果把自然语言处理比作从矿砂中淘金子,那么业界主流算法的方向是从矿砂中将金砂挑出来,而遗忘算法的方向则是将砂石筛出去,虽然殊途但同归,所处理的任务也都是主流中所常见。
本系列文章将逐一讲解遗忘算法如何以O(N)级算法性能实现:
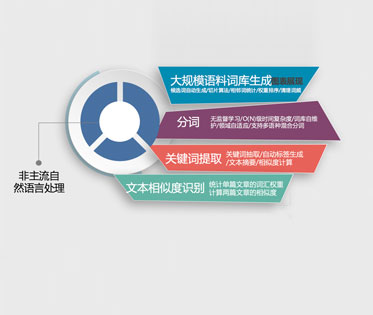
1、大规模语料词库生成
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
2、分词(基于上述词库技术)
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.3、领域自适应、跨语种(继承自词库特性)
3、词权值计算
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
4、共现词典生成(词云、知识图谱)
5、模板自动抽取




